由于工作的需要,我想要将繁体字版的《粤港澳大湾区发展规划纲要》的高频词语做成词云(标签云)形式。于是经过多个软件的探索和尝试,最终发现效果非常不理想,在一个知乎问答里面,我了解到R这个英文单词,本着一探到底的好学精神,我又粗浅地掌握了一门技能:用R语言做中文词云。
1、关于R语言及安装
R语言在我看来是一个需要用各种包(程序包)配合来进行操作的。总之如果做中文词语,需要安装 Rjava,Rwordseg这两个包。
在安装这两个包之前,必须在电脑安装JAVA,并进行相应的环境配置。详细可见:
2、R中文分词包( Rjava,Rwordseg )的安装
3、做词云仍需要wordcloud包,关于 wordcloud2的安装与设置
所有包包安装准备就绪后,正式开始做词云啦!
#加载分词以及做词云所用的包
library(rJava)
library(Rwordseg)
library(wordcloud2)
#读入文本数据
#引入文档 的指令
myfile <- read.csv(“D:/myfile/DWQ.txt“, header = TRUE,stringsAsFactors = FALSE)
关于读取文本的指令,@妖精的尾巴导入CSV、TXT文件博客有详细的说明
把繁体字的《粤港澳大湾区发展规划纲要》在word先删除一些字眼,比如:的/为/和…… ,存为txt文档。
其实是可以#引入停用表 来解决的。所谓停用表,就是在分析过程中剔除或者过滤某些词/无意义的词。中文文本分析是非常重要的过程,而停用表的选择也很重要。
我尝试过普通的停用表,以及#进行分词设计,由于纲要的特殊性,还是不能取得很好的效果。分词会把“粤港澳”分成“粤”、“港澳”,“大湾区”分成“大”、“湾区”。而我更想关注产业和态度方向,因此我在整理文档的时候就删除了:
粵港澳大灣區、粵港澳、港澳、 大灣區、發展、建設、提供、具有、形成、的、和、爲、在、與、就、等、及、以、第一/二/三/四/五節……这些词语。
#自定义词典
Rwordseg是有默认词典的,但有一些新词需要额外注意,因此可以自己设定一些关键词,直到达到理想的分词效果。
#手动增加常用词 經過嘗試,增加繁體字後,仍然無法識別,简体字则可以。
insertWords(c(“九市”,”大灣區”,”一帶一路”,”人民币”,”擴大”,”低碳”))

#进行中文分词生成词云数据
#中文分词
myfile.words <- unlist(lapply(X = myfile, FUN = segmentCN))
#去停词
同时也可以导入去停词表,去掉分词中的停用词,包括“的”、“在”、“就”……无意义的词汇。由于文件的特殊性,加上停词表都是简体字,所以我已经提前处理txt文档的个别词语。
网上有很多别人整理的停词表,下载下来存为txt文档。
#引入停用词表
stopwords <- read.csv(“D:/自行下载的停词表.txt”,
header = FALSE, stringsAsFactors = FALSE)
#设置去停词函数
RemoveStopWords <- function(x,stopwords) {
temp <- character(0)
index <- 1
xLen <- length(x)
while (index <= xLen) {
if (sum(stopwords == x[index]) < 1)
temp<- c(temp, x[index])
index <- index + 1
}
temp
}
#对myfile.words去停词
words <- lapply(myfile.words, RemoveStopWords, stopwords)
#生成词数据
生成词云数据(包含具体词语和频数)
wordsNum <- table(unlist(myfile.words )) 如果你去停词了,记得j将myfile.words改为words
wordsNum <- sort(wordsNum, decreasing = TRUE)
wordsData <- data.frame(wordsNum)
wordsData$Var1 <- as.character(wordsData$Var1)
#提取前200个高频词做词云
finaldata <- wordsData[1:200, ]
#制作词云
wordcloud2 函数支持输入自定义图片来作为词云的背景形状,需要注意的是自定义图片的时候需要 “黑白” 的来作为词云的形状输入。
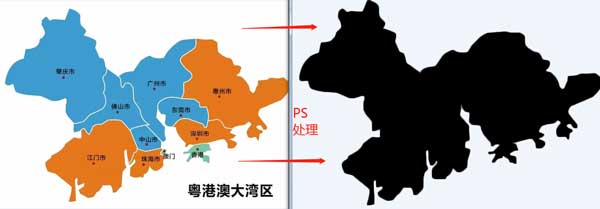
#导入图片
figPath = system.file(“examples/dawanqu.png”,package = “wordcloud2”)
#生成词云
wordcloud2(finaldata, figPath = figPath, size = 1,color = “random-light”)

注意:生成后,弹出网页,如果看不到图片,可以手动刷新几次。如果color的参数你选择的是色系,可以通过刷新,每个词语的颜色和位置都会变化,直至选到你满意的为止。
颜色的参数可以参考这张图,同时,还有可以选择‘random-dark’以及‘random-light’,这些颜色色系。

折磨了自己这么久,真的很感谢随处可得的网友共享!但是要一一筛选有用的,对于首次接触R的我是很费神的。感谢!
@bushijiangshan:用R语言做自己的微信聊天记录词云
@郎大为:可能是目前最好的词云解决方案 wordcloud2
以下是有关分词的,这次还没有很深入的研究
@WealdPoem:使用R语言进行分词与词云
@王亨:使用R语言进行中文分词
@喜欢算法的女青年: R系列分词、去停用词、画词云(词云形状可自定义)
@悟乙己:R语言︱文本挖掘之中文分词包——Rwordseg包(原理、功能、详解)
